Introduktion
Introduktion till länkade data
Bakgrund
1990 skapade Tim Berners-Lee grunden för World Wide Web genom att kombinera principerna bakom internet med hypertext. I korthet introducerade han principer för att identifiera (URL:er), publicera (HTML) och hämta (HTTP) dokument. 2006, 16 år senare, lanserar Tim Berners-Lee Länkade Data, förkortat LD, som ett sätt att skapa en webb av data i en design issue. Skillnaden mot den vanliga webben är att länkade data handlar om att länka samman ting och dess beskrivningar snarare än dokument.

Interestingly, data is relationships. This person was born in Berlin; Berlin is in Germany. And when it has relationships, whenever it expresses a relationship then the other thing that it's related to is given one of those names that starts HTTP. So, I can go ahead and look that thing up. So I look up a person -- I can look up then the city where they were born; then I can look up the region it's in, and the town it's in, and the population of it, and so on. So I can browse this stuff.
So that's it, really. That is linked data.
The next web, by Tim Berners Lee at TED2009.
På sista tiden har intresset för det som kallas öppna data växt kraftigt. Öppna data innebär att man gör data tillgängliga över Internet för att förenkla användning, såväl väntad som oväntad. Att göra sina data tillgängliga som öppna data är ett bra första steg, men saknar den potential som länkad data har. Något förenklat kan man formulera skillnaden så här:
Länkade data tillför länkar och ett enhetligt format (RDF) som saknas hos öppna data.
Oftast är även länkade data tillgängligt öppet och benämns då länkade öppna data. På engelska används akronymen LOD för den engelska benämningen Linked Open Data. I denna vitbok håller vi dock fast vid benämningen länkade data för att markera att det finns fördelar oavsätt om datan är allmänt tillgänglig (öppen) eller inte.
De viktigaste begreppen på 5 minuter
Vad är Länkade Data?
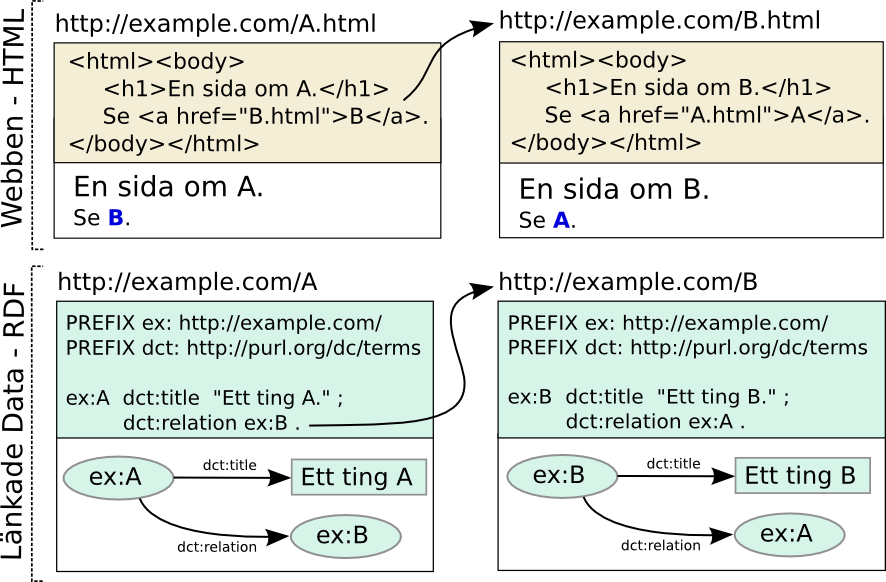
Länkade data handlar om att komplettera den existerande webben av dokument med en webb av data. Det första vi behöver förstå är att länkade data handlar om påståenden om ting, där ting kan vara personer, platser, mediciner, historiska händelser, bilder, filmer, textdokument osv. Konkret räcker det att följa tre principer:
- addresserbarhet - ge varje ting en URI (en webbadress) som gör att påståenden kan hämtas via HTTP
- enhetlig informationsmodell - används språket RDF för att uttrycka påståenden om ting
- länka ihop - förbind ting med varandra genom relationer av olika slag, gärna mellan olika datakällor
Varför ska jag publicera Länkade Data?
Att använda länkade data ger många fördelar, bland annat:
- lättare att förstå och återanvända varandras data
- minska duplicering och fokusera på de egna datas specifika och unika mervärden (genom att länka till andras data)
- din data blir bättre tillgänglig på webben och i sökmotorer
- etablerade tekniker för maskinell bearbetning möjliggörs (då användning av länkade data innebär att semantiken hos datat klargörs)
Hur publicerar jag Länkade Data?
Identifiera vilka ting du har och ge dem webbadresser, tex: http://data.min-domän.se/produkt/15
Skapa lite påståenden om dina ting och lägg upp dem på respektive webbadress. Återanvända gärna etablerade vokabulärer, i exemplet nedan används Dublin Core Terms (förkortat dct). Exempelet använder turtle syntaxen då den är tämligen enkel att läsa:
PREFIX ex: <http://data.min-domän.se/produkt>
PREFIX dct: <http://purl.org/dc/terms/>
ex:15 dct:title "Produkt 15";
dct:description "Produkt nummer 15 erbjuder en fantastisk...";
dct:created "2014-09-09".
Lägg sedan gärna till påståenden i form av relationer (länkar) både mellan dina egna ting och till externa ting.
ex:16 dct:title "Produkt 16";
dct:partOf ex:15;
dct:relation <http://dbpedia.org/page/Bread>.
Klart! Länkade data är inte svårare än så. Dock tillkomer som alltid frågor kring underhåll, integration med existerande tekniska plattformar, intern kompetens kring informationsmodellen osv.
Webben och länkade data
Webben av idag har stor spridning och är i många fall det gemensamma kitt som binder samman aktörer över kulturella och språkliga gränser. Webben används ofta till både spridning och inhämtning av information samt till att bygga mer avancerade webbapplikationer. Trots denna vida användning är webben i grunden tämligen enkel och dess tekniska beståndsdelar innefattar i huvudsak:
- URI - ett enhetligt sätt att addressera olika informationsresurser (ofta webbsidor)
- HTTP - ett protokoll som används för att hämta och skicka information
- HTML - ett format för att presentera och interagera med information
- Länkar - ett sätt att binda samman informationsresurser
Webben är trots sina vida användningsområden i huvudsak ett presentationsmedium för människor. Det innebär att webben, och framförallt HTML, oftast inte lämpar sig för att utbyta information mellan system.
För att utbyta information mellan system är istället det snarlika initiativet Länkade data ett bättre alternativ. Precis som webben bygger länkade data på användning av URI:er och HTTP, men istället för HTML används RDF. I korthet kan man säga att RDF används för att uttrycka påståenden om ting, där ting är vad som helst som kan identifieras av en URI. Det är alltså inte bara webbsidor som identifieras av URI:er (webbaddresser) utan även fysiska föremål, historiska händelser, abstrakta begrepp osv. Det vill säga, vi kan ge URI:er även till ting som inte har en given digital representation. Sammanfattningsvis, länkade data innefattar i huvudsak följande tekniska beståndsdelar:
- URI - ett enhetligt sätt att addressera ting
- HTTP - ett protokoll som används för att hämta påståenden om ting via deras URI:er
- RDF - ett språk för att uttrycka påståenden om ting
- länkar - påståenden om relationer mellan ting
Bilden nedan visar en jämförelse mellan webben och länkade data:
Stjärnmodellen
I samband med öppna data och länkade öppna data använder man ofta en femstjärnig skala för att markera hur tillgänglig datan är:
★ gör din information tillgänglig på webben under en öppen licens
(även svårbearbetade format som skannade dokument är ok)
★★ gör informationen tillgänglig som strukturerad data
(t. ex., Excel-format istället för en bild av en tabell)
★★★ använd icke-proprietära format
(t. ex., CSV istället för Excel)
★★★★ använd URI:er för att identifiera ting,
och RDF för att uttrycka påståenden om dem
★★★★★ länka din data till andras data, det ger sammanhang
Nedan beskrivs fördelar med stjärnnivåerna, notera att fördelar ackumuleras ju fler stjärnor man når.
★ En stjärna - data tillgängligt digitalt
Om du lägger ut din data så att den är digitalt tillgänglig och det är tydligt att folk får använda datan (i form av en licens) så får du alltid en stjärna. Till exempel, om man redan har information tillgänglig på vanliga webbsidor och kompletterar hur informationen får vidareanvändas är första stjärnan säkrad.
Det är ett stort steg att gå från att behöva explicit begära data från en organisation till att informationen finns tillgänglig digitalt.
★★ Två stjärnor - öka datakvalitéten
Att dela ut ett format där data är tillgängligt på ett maskinprocessbart sätt utan att man behöver använda någon form av riskfylld extraheringsprocess gör att andra kan förlita sig på datan i större utsträckning. Insatsen för att använda datan i andra sammanhang har sjunkit betydligt och två stjärnor är säkrade.
★★★ Tre stjärnor - öppna data
Med tre stjärnor minskar man behovet av investeringar i proprietär teknologi hos de som vidareutnyttjar datan. Då man förlitar sig på öppna format som antingen är väldigt enkla (t. ex. CSV-formatet) eller väl dokumenterade skapar man förutsättningar för mer långsiktig hållbar data. Man minskar även risken för felaktig bearbetning av information när proprietära format hanteras av tredje parts mjukvara (särskilt när fullständig dokumentation om formatet saknas).
★★★★ Fyra stjärnor - enhetligt informationsuttryck och tydlig semantik
Med den fjärde stjärnan uppnås flera saker:
- Genom att man delat upp datan i ting som har globala identifierare, URI:er, möjliggör man för andra att referera till den egna datan på ett sätt som är standardiserat och effektivt.
- Dataintegration med andra parter förenklas då det datauttryck man väljer inte är bundet till det egna datalagret. Istället beskriver man sin data med hjälp av existerande termer, ofta anpassar och kombinerar man en eller flera existerande informationsmodeller efter egna behov. Detta innebär att när den egna datan ska vidareutnyttjas kan andra parter redan ha kännedom eller till och med utvecklat stöd för att förstå delar av informationsmodellen.
- Den informationsmodell man utvecklat är med stor sannolikhet mer genomtänkt då den är en vidareutveckling av tidigare informationsmodeller.
- Då datan uttrycks med RDF, ett standardiserat språk för hantera information så finns redan många mjukvarubibliotek och tjänster som kan användas för att skapa, validera, lagra, maskinellt bearbeta, kombinera, redigera och utforska datan med existerande frågespråk.
★★★★★ Fem stjärnor - länkade öppna data
Den femte stjärnan ger flera ytterligare fördelar:
- Förtydliga din data genom att länka till väletablerade och väl uttänkta termer/begrepp istället för att skapa egna eller skriva fritext.
- Använd data/begrepp/termer från andra datakällor direkt när behov uppstår utan att först behöva fokusera på tekniska aspekter av dataintegration som import, konvertering och drift/underhåll.
- Effektivt använd länkning kan leda till att öka dataspecialisering då du kan fokusera på att underhålla de delar av datan som är unik för din organisation och mindre med information som redan finns i andra datakällor.
- Länkar till andra datakällor ökar förtroendet för att din data är genomtänkt på ungefär på samma sätt som referenser i artiklar visar på att informationen är förankrad i ett större sammanhang.
- Länkar ut ökar din datas synlighet då det blir en del av det större länkade data molnet vilket i ett längre perspektiv kan leda till återanvändning i nya sammanhang, dvs. i form av länkar in.
Vikten av återanvändning
Återanvänding av existerande termer är en viktig aspekt vid publicering av länkade data. Att återanvända väletablerade termer ökar sannolikheten att applikationer kan konsumera publicerade länkade data utan att det krävs särskilda anpassningar för olika datamängder. Det finns alltid situationer där befintliga termer inte exakt matchar behovet. I sådana fall är det rekommenderat att skapa en ny term som länkar tillbaka till det som förfinas (s.k. "refinements") eller är relaterat. Utan återanvändning eller länkar mellan relaterade termer förlorar man en av de mest kraftfulla egenskaperna av länkade data och man löper risk att det publiceras datamängder som har högst begränsad interoperabilitet med andra data.
Länkade data - en global rörelse
Länkade data introducerades av Webbens grundare sir Tim Berners-Lee 2006 i en inflytelserik Linked Data Design Note. Ett sätt att mäta i vilken omfattning länkade data används är att se hur många dataset och hur många påståenden som publicerats över tiden. Till exempel så ökade antalet publicerade påståenden från 2 miljarder 2007 till 30 miljarder 2011. Antalet dataset har också ökat dramatiskt vilket kan ses i de visualiseringar som gjordes av det så kallade LOD-molnet. Tyvär har ingen visualisering gjorts sedan 2011, då det såg ut så här:
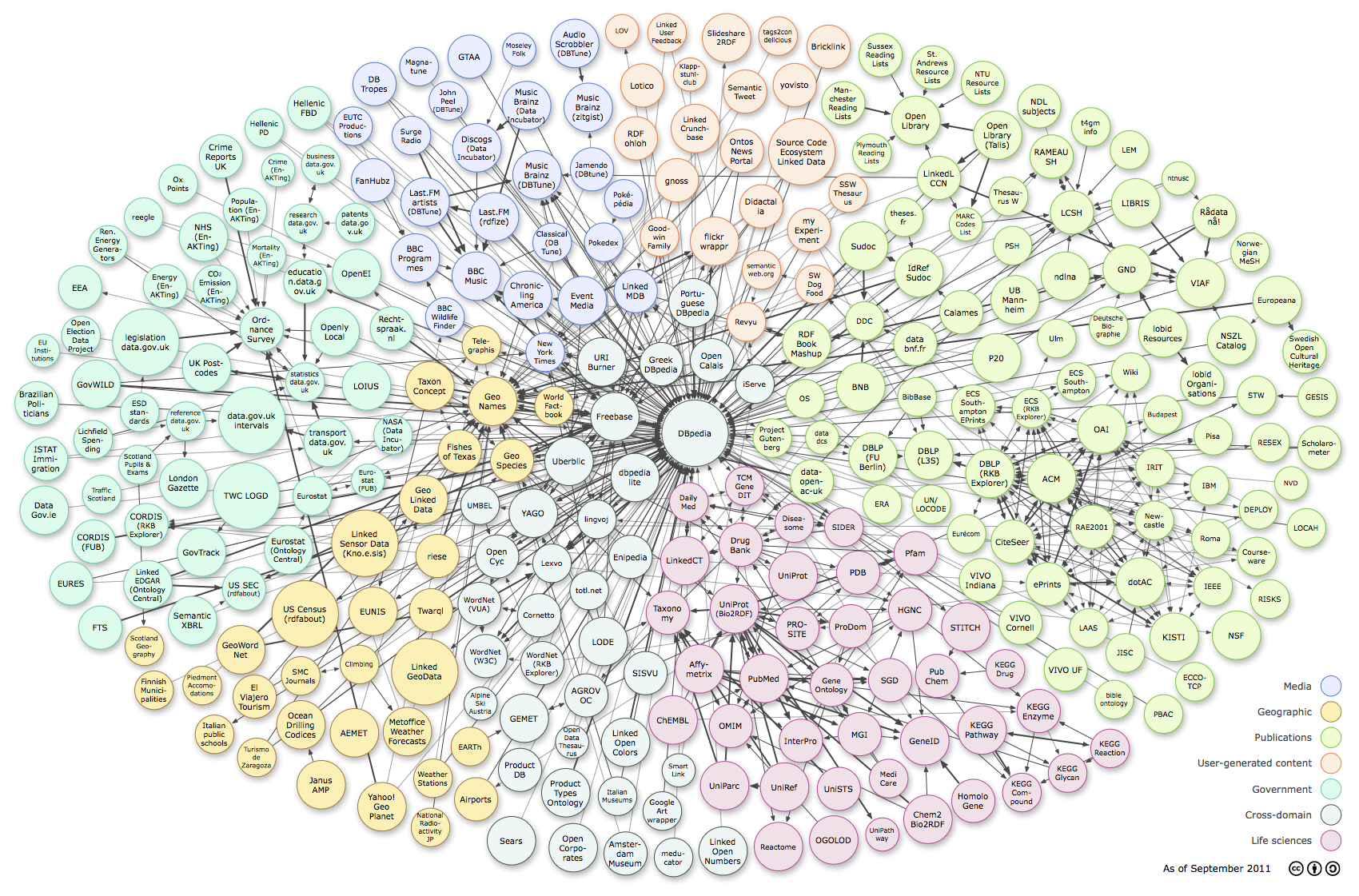 Linking Open Data cloud diagram, by Richard Cyganiak and Anja Jentzsch. http://lod-cloud.net/
Linking Open Data cloud diagram, by Richard Cyganiak and Anja Jentzsch. http://lod-cloud.net/
En indikation på att det fortsatt att växa sedan dess kan man få genom att söka fram alla dataset på datahub.io, vid skrivande stund är de 898 stycken. Detta ska jämföras med de 295 som ingick i visualiseringen 2011. Det är också troligt att det finns ett stort mörkertal med dataset som antingen inte registrerats alls eller registrerats i nationella register som inte alltid aggregeras i datahub.io.
Innehållsmässigt spänner dataseten över de flesta områden till exempel, myndighetsdata, biomedicin, media, geografisk information osv.